مهمترین انواع regression
رگرسیون خطی (linear regression)
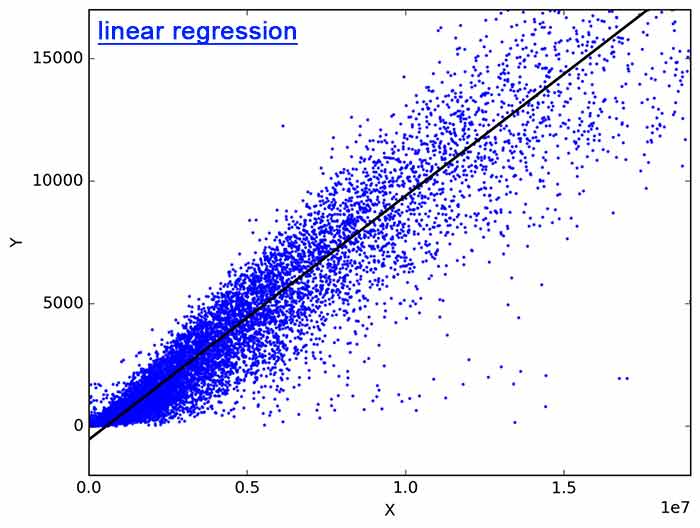
رگرسیون خطی رایج ترین تکنیک مورد استفاده این آنالیز آماری است. هدف آن یافتن معادلهای برای یک متغیر مبهم پیوسته به نام Y است که تابعی از یک یا چند متغیر (X) خواهد بود. بنابراین، رگرسیون خطی میتواند مقدار Y را زمانی که فقط X شناخته شده باشد، پیش بینی کند و به هیچ عامل دیگری بستگی ندارد. Y به عنوان متغیر ملاک شناخته می شود در حالی که X به عنوان متغیر پیشگو یا مستقل شناخته می شود. هدف یافتن منطبقترین خط به نام خط رگرسیون از طریق نقاط است.
رگرسیون خطی را میتوان به تحلیل رگرسیون چندگانه و تحلیل رگرسیون ساده تقسیم کرد. در خطی ساده، فقط یک متغیر مستقل X برای پیشبینی مقدار متغیر تایع Y استفاده میشود. از طرف دیگر در چندگانه، از بیش از یک متغیر مستقل برای پیشبینی Y استفاده میشود. البته در هر دو مورد فقط یک متغیر Y وجود دارد و تنها تفاوت در تعداد متغیرهای مستقل است.
به عنوان مثال، اگر اجاره یک آپارتمان را فقط بر اساس متراژ مربع پیش بینی کنیم، یک رگرسیون خطی ساده است. از سوی دیگر، اگر اجاره را بر اساس عوامل متعددی پیش بینی کنیم; متراژ مربع، موقعیت ملک و قدمت ساختمان، سپس به نمونه ای از تحلیل چندگانه تبدیل میشود.
رگرسیون لجستیک (Logistic Regression)
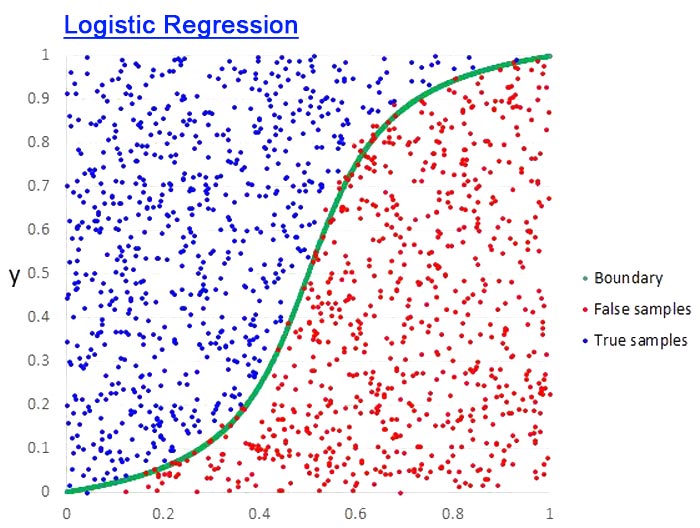
برای درک اینکه لجستیک چیست، باید با درک تفاوت آن با مدل خطی شروع کنیم. برای درک تفاوت بین رگرسیون خطی و لجستیک، ابتدا باید تفاوت بین یک متغیر پیوسته و یک متغیر طبقهای را درک کنیم.
متغیرهای پیوسته مقادیر عددی هستند. آنها بین هر دو مقدار داده شده دارای تعداد نامتناهی هستند. به عنوان مثال می توان به جمعیت یک شهر اشاره کرد. از سوی دیگر، متغیرهای طبقهای دارای گروهها یا دستههای مجزا هستند. آنها ممکن است نظم منطقی داشته باشند یا نداشته باشند. به عنوان مثال می توان به جنسیت، روش پرداخت، گروه سنی و … اشاره کرد.
در linear regression، متغیر وابسته Y همیشه یک متغیر پیوسته است. اگر متغیر Y یک متغیر طبقهای باشد، نمیتوان رگرسیون خطی را اعمال کرد. در صورتی که Y یک متغیر طبقهای است که فقط 2 گروه دارد، می توان از رگرسیون لجستیک استفاده کرد. چنین موضوعاتی به عنوان مسائل طبقه بندی باینری نیز شناخته میشوند. همچنین درک این نکته مهم است که رگرسیون لجستیک استاندارد فقط برای مسائل طبقه بندی باینری قابل استفاده است. اگر Y بیش از 2 گروه داشته باشد، به یک طبقه بندی چند کلاسه تبدیل می شود و دیگر قابل اعمال کردن نیست.
یکی از بزرگترین مزیتهای این تحلیل آماری که آن را به یک تکنیک مدلسازی پیشبینیکننده ارزشمند برای تجزیه و تحلیل داده تبدیل کرده است، این است که میتواند امتیاز احتمال پیش بینی یک رویداد را محاسبه کند.
رگرسیون چند جملهای (Polynomial Regression)
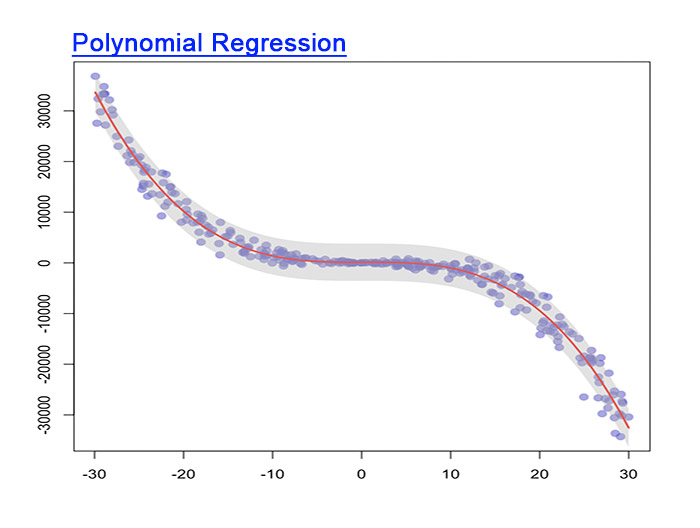
اگر توان متغیر مستقل (X) بیش از 1 باشد، به آن رگرسیون چند جمله ای میگویند. معادلهی آن به شکل زیر است:
y= a +b*x^3
بر خلاف رگرسیون خطی، که یک خط مستقیم است، در چند جملهای، بهترین خط، منحنی است که در نقاط مختلف داده قرار میگیرد. مهم است که منحنی را به سمت انتها بررسی کنید و مطمئن شوید که شکل و شمایل آن درست باشد. هر چه چند جمله ای بالاتر باشد، احتمال بیشتری برای ایجاد نتایج عجیب در طول تفسیر بیشتر است.
رگرسیون گام به گام (Stepwise Regression)
زمانی استفاده میشود که چندین متغیر مستقل وجود داشته باشد. ویژگی خاص آن این است که متغیرهای مستقل به طور خودکار و بدون دخالت انسانی انتخاب میشوند. مقادیر آماری مانند R-square و t-stats برای شناسایی متغیرهای مستقل مناسب استفاده میشوند. این تحلیل آماری اغلب زمانی استفاده میشود که مجموعه دادهها ابعاد بالایی دارند. زیرا هدف آن به حداکثر رساندن توانایی پیشبینی مدل با حداقل تعداد متغیر است. رگرسیون گام به گام بر اساس شرایط از پیش تعریف شده، متغیرهای کمکی را یکی یکی اضافه یا حذف میکند. تا زمانی که مدل برازش نشود این کار را ادامه میدهد.
رگرسیون ستیغی (Ridge Regression)
هنگامی که متغیرهای مستقل همبستگی بالایی دارند (چندخطی)، از ستیغی استفاده میشود. زمانی که متغیرهای مستقل همبستگی بالایی دارند، واریانس برآوردهای کوچکترین توانهای دوم بسیار بزرگ است. در نتیجه مقدار مشاهده شده از مقدار واقعی انحراف زیادی دارد. رگرسیون ریج این مشکل را با افزودن درجهای از بایاس به تخمینهای رگرسیون حل میکند.
رگرسیون لاسو (Lasso Regression)
درست مانند روش قبلی، رگرسیون لاسو نیز از یک پارامتر انقباضی برای حل مسئله چند خطی استفاده می کند. همچنین با بهبود دقت به مدلهای رگرسیون خطی کمک میکند. تفاوت آن با ستیغی در این است که تابع جریمه به جای مربعها از مقادیر مطلق استفاده میکند.
رگرسیون شبه الاستیک (ElasticNet Regression)
شبه الاستیک، دو مدل قبل را با هم ترکیب کرده و معایب آنها را حذف کرده است و جایگرین مطمئنی برای آنها است. در این روش یک قاعده سازی 1 و 2 همزمان روی مدل اعمال میشود. در نتیجه به صورت زیر نوشته میشود:
min(∑ϵ2+λ1∑βi+λ2∑|βi|)
و با درنظر گرفتن مدل خطی میتوان آن را به صورت زیر نوشت:
min(∑yi–(β0+β1X1+β2X2+…+βkXk)2+λ1∑β2i+λ2∑|βi|)
سخن آخر
تحلیل معرفی شده پایه و اساس علم داده است. به همین دلیل آگاهی از انواع آن و زمان استفاده از هرکدام مهم است. در صورتی که نیاز به اطلاعات بیشتر دارید تیم آمار برتر همراه شما خواهد بود.
